Authors: Simon Rouard1,2, Yossi Adi1,3, Jade Copet1, Axel Roebel2, Alexandre Défossez4
Affiliations: 1FAIR Meta, 2IRCAM - Sorbonne Université, 3Hebrew University of Jerusalem, 4Kyutai
Accepted at ISMIR 2024: Read the paper
Code and pretrained model available: on the audiocraft repository.
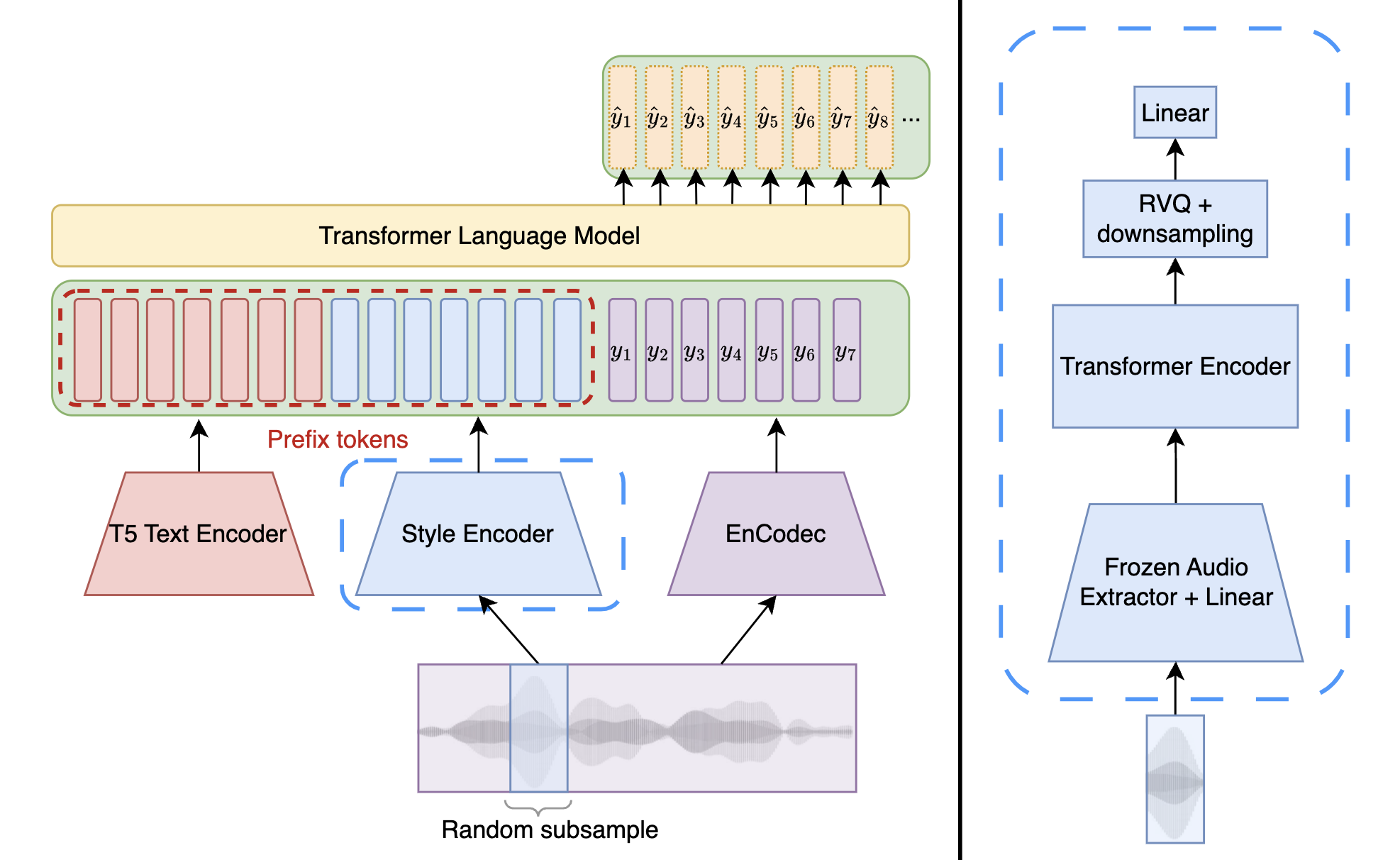
We present here a MusicGen model that handles style and text conditioning. The style conditioner uses a few seconds audio excerpt as a condition and allows the model to generate music that is similar to it. Our model is trained on 30 seconds which means that we can sample up to 30 seconds long excerpt. We can use the style conditioner by itself, or combine it with the text conditioner. Here are some examples of music generated with the style conditioner only:
| Style Condition | Ex. 1 | Ex. 2 |
|---|---|---|
| Style Condition | Ex. 1 | Ex. 2 | Ex. 3 | Ex. 4 | Ex. 5 |
|---|---|---|---|---|---|
| Textual description: "Rock opera with drums bass and an electric guitar. Epic feeling" | ||||
| Style Condition | Ex. 1 | Ex. 2 | Ex. 3 | Ex. 4 |
|---|---|---|---|---|
| Textual description: "Chill lofi remix" | ||||
| Style Condition | Ex. 1 | Ex. 2 | Ex. 3 | Ex. 4 |
|---|---|---|---|---|
| Textual description: "8-bit old video game music" | ||||
| Style Condition | Ex. 1 | Ex. 2 | Ex. 3 | Ex. 4 |
|---|---|---|---|---|
| Textual description: "Indian music with traditional instruments" | ||||
| Style Condition | Ex. 1 | Ex. 2 | Ex. 3 | Ex. 4 |
|---|---|---|---|---|
| Textual description: "80s New Wave with synthesizer" | |||||
| Style Condition | Ex. 1 | Ex. 2 | Ex. 3 | Ex. 4 | Ex. 5 |
|---|---|---|---|---|---|
Here are some samples from our internal test set (used for the human study of Tab.1):
| Comparison with baselines | |||||
| Conditioning | Textual Inversion | MusicGen Continuation | MusicGen w. CLAP conditioner | Our Model w. EnCodec and 2 RVQ | Our Model w. MERT and 2 RVQ |
|---|---|---|---|---|---|
Here are some samples from our internal test set (used for the human study of Tab.2). We compare 4 different levels of quantization (q=1, q=2, q=4). The bigger the level is, the larger is the bottleneck. When q increases, the generated music is closer to the conditioning.
| Influence of the quantization level | |||
| Conditioning | Our Model w. MERT and 1 RVQ | Our Model w. MERT and 2 RVQ | Our Model w. MERT and 4 RVQ |
|---|---|---|---|
During training time, the model is trained with aligned text and style conditioning (i.e. both textual description and the audio of style conditioning comes from the same song). However, at inference time, we can mix different textual description in order to generate great remixes.
Since the text conditioning is less informative than the style conditioner, we use double classifier free guidance (double CFG) to boost the text modality. We showcase the effectiveness of double CFG with a first example. The model used has a MERT feature extractor and 2 RVQ.
We let \( \alpha =3 \) and explore \( \beta \in \{1, 2, 3, 4, 5, 6, 7, 8, 9\} \). Note that \( \beta = 1 \) is equivalent to normal CFG.
Style Conditioning:
| Influence of the \( \beta \) coefficient in double CFG | ||||
| \( \beta = 1 \) | \( \beta = 2 \) | \( \beta = 3 \) | \( \beta = 4 \) | \( \beta = 5 \) |
|---|---|---|---|---|
| \( \beta = 6 \) | \( \beta = 7 \) | \( \beta = 8 \) | \( \beta = 9 \) |
|---|---|---|---|